

Optische tekenherkenning (OCR) is het technologische proces van het herkennen en omzetten van zowel handgeschreven als gedrukte karakters in bewerkbare en doorzoekbare gegevens. Het heeft twee primaire functies:het elimineren van handmatige gegevensinvoer en automatisch informatie extraheren . Als u bijvoorbeeld een papieren contract wilt digitaliseren en bewerken, kunt u ofwel veel tijd besteden aan het intoetsen van het document, of u kunt een scanner/foto en OCR gebruiken om het bestand binnen enkele seconden om te zetten in een uitvoerbaar bestand.
OCR-technologieën bereiken nu een zeer hoge mate van nauwkeurigheid in tekenherkenning , van meer dan 99%. De uitdaging van vandaag is om gegevens in afgedrukte of gescande documenten te lokaliseren en te extraheren door de relevante gecombineerde informatiereeksen te identificeren die moeten worden geëxtraheerd. Dit is vooral een uitdaging in het geval van ongestructureerde documenten en tabellen. Natuurlijke taalverwerking (NLP) en machine learning kunnen worden gebruikt om gegevens uit documenten te identificeren en te extraheren en direct functies inschakelen die anders niet mogelijk zouden zijn (d.w.z. kruisvalidatie of optellen van getallen in tabellen). Veel OCR-leveranciers maken al gebruik van deze technieken om de functionaliteit van de OCR-tools die ze aanbieden te verbeteren.
In digitaliseringsprojecten wordt OCR-technologie vaak gebruikt in combinatie met workflowtools om processen te automatiseren en handmatig werk te verminderen. Deze tools verzamelen, ophalen, verwerken, bewerken, archiveren of doorsturen van gegevens en documenten.
OCR is slechts een middel om een doel te bereiken, en het moet worden gecombineerd met geavanceerde analysesoftware om echte functionele waarde toe te voegen, door gegevens te integreren die door OCR-engines uit documenten zijn gehaald met AI-aangedreven systemen, voor veel potentiële gebruiksgevallen, zoals fraudedetectie , naleving van regelgeving of procesautomatisering.
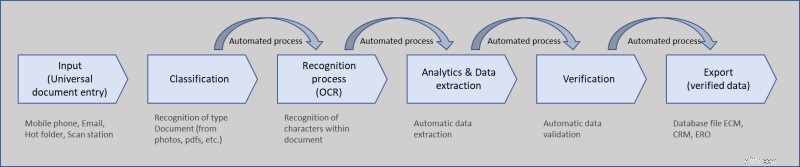

Proces voor kredietrisicobeheer in het bankwezen: Kredietbeoordelingen kunnen zeer tijdrovend zijn, omdat ze gebruik maken van financiële documenten die origineel, gefotokopieerd of gescand zijn. Dit houdt in dat elk regelitem handmatig wordt ingevoerd in een IT-systeem ten behoeve van de beoordeling. Dit proces heeft een vrij hoog risico op invoerfouten, met slechts beperkte gegevensoverdrachten, met als gevolg dat de financiële analyse voor kredietdoeleinden onbetrouwbaar kan zijn. OCR in combinatie met AI kan niet alleen gescande financiële overzichten digitaliseren, maar kan ze ook omzetten in leesbare en doorzoekbare datasets die toegankelijk zijn voor alle IT-systemen. Hiermee kan een deel van het werk van de kredietanalist worden geautomatiseerd. In dit proces is de eerste stap het digitaliseren van jaarrekeningen met behulp van OCR. Machine learning-algoritmen leren het systeem vervolgens de onderliggende patronen in de boekhoudkundige overzichten te onderscheiden, de benodigde gegevens te identificeren en te extraheren. Dit levert een tijdwinst op van ongeveer twee tot vier uur per kredietbeoordeling, en de kredietanalist kan zich ook meer richten op de feitelijke kredietrisicoanalyse en beter geïnformeerde kredietbeslissingen nemen.
Over het algemeen kan een goed ontwikkeld/getraind systeem gemakkelijk nauwkeurigheidsniveaus van meer dan 90% bereiken bij het extraheren van gegevens uit MKB-balansen van MKB-bedrijven, klantonboarding en andere verschillende documenten, wat betekent dat automatisering vaak nauwkeuriger is dan wanneer het proces handmatig wordt uitgevoerd, maar voor een fractie van de kosten en tijd. Over het algemeen kan OCR-technologie tijd besparen door handmatige processen te verminderen of te elimineren, de productiviteit te verbeteren en de kans op fouten of fraude te verkleinen.
Een aantal leveranciers biedt kant-en-klare OCR . Enkele van de belangrijkste producten die momenteel op de markt zijn, zijn ABBYY FlexiCapture, ABBYY Vantage, Google's Vision AI, Amazon Textract en Microsoft's Computer Vision.
Onze klant, een toonaangevende D-SIB, heeft verschillende digitaliseringsprojecten in de kredietsector geïnitieerd, waaronder de ontwikkeling van een mobiel B2C-hypotheekplatform. Met deze app kunnen eindklanten op afstand hypotheken aanvragen, wat het aanvraag- en goedkeuringsproces vereenvoudigt en versnelt. Aangezien het kredietverleningsproces in Zwitserland nog steeds een groot aantal papieren formulieren omvat, zocht de bank een oplossing voor documentidentificatie en geautomatiseerde gegevensextractie door de eindgebruikers zelf, om klanten te ontlasten van de vervelende taak om de benodigde gegevens handmatig in te voeren voor de leningaanvraag.
Deloitte was verantwoordelijk voor het ontwikkelen van deze capaciteiten en kon in samenwerking met ABBYY binnen korte tijd een OCR-oplossing inzetten met ABBYY FlexiCapture, om relevante gegevens met hoge nauwkeurigheid (meer dan 90% na training) te extraheren uit belastingaangiften, salariscertificaten, nationale identificatiedocumenten, maar ook buitenlandse verblijfsvergunningen en pensioenfondsverklaringen. Deloitte paste zijn expertise toe bij de technische implementatie van OCR-oplossingen en zijn kennis van de wettelijke vereisten en de huidige best practices in Zwitserse kredietverleningsprocessen. Het was belangrijk om een reverse engineering-aanpak toe te passen om de gegevenspunten die nodig zijn voor de kredietbeslissing te identificeren en te vereenvoudigen, in overeenstemming met de kredietrisicobereidheid en het kredietmodel van de klant. om een platform te ontwikkelen voor het snel verwerken van hypotheekaanvragen met een flexibele configuratie van invoer- en uitvoerinterfaces, wat een naadloze integratie via API mogelijk maakte voor mobiele gebruikers, waardoor hypotheekaanvragers een intuïtieve klantreis kregen.
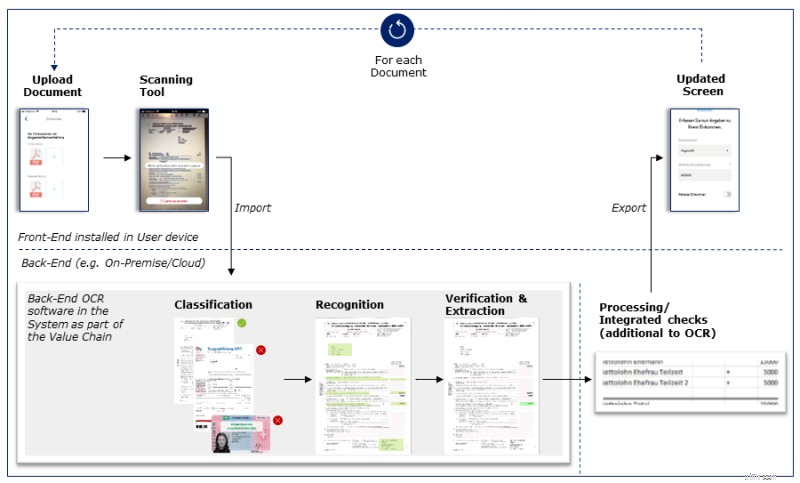
Het proces van gegevensverzameling en -extractie is als volgt:De klant uploadt ofwel een scan van het vereiste document of maakt een foto met de smartphone rechtstreeks via het mobiele hypotheekaanvraagplatform. Het geüploade document wordt vervolgens geanalyseerd in FlexiCapture en automatisch geclassificeerd. Afhankelijk van het document extraheert FlexiCapture bepaalde velden met de vereiste relevante informatie. Vervolgens wordt de nauwkeurigheid van de tekenherkenning getest en als deze boven een bepaalde drempel komt (in dit geval 90%) worden de gegevens automatisch geëxporteerd voor verder gebruik in de hypotheekaanvraag. Als de nauwkeurigheidstest onder de drempel valt, heeft de gebruiker de mogelijkheid om de geëxtraheerde informatie te bekijken en handmatig te corrigeren.
Bij Deloitte, met onze uitgebreide ervaring met het implementeren van de nieuwste technologieën en onze expertise in de financiële dienstverlening, kunnen we u helpen om de efficiëntie in uw processen te verhogen, kosten te verlagen en waarde te ontsluiten. Aarzel niet om contact met ons op te nemen voor verdere vragen.
Wat is een authentiek merk en hoe kun je dat zijn?
Wat is een balans en hoe kan ik deze gebruiken om mijn bedrijf te beheren?
Hoe de cloud workflow en processen transformeert...
Wat is complexiteitsbias? En hoe ga je ermee om?
Wat is Hindsight Bias? En hoe u dit kunt vermijden?
Wat is een slechte bank? En hoe het de banksector kan doen herleven?
Waarom een beurscrash en hoe je er een kunt identificeren!