
De financiële wereld wordt geteisterd door een ziekte die zo wijdverspreid en algemeen voorkomt dat zelfs 'experts' het niet met de vereiste ernst lijken te nemen. De ziekte, die op korte termijn geen tekenen van ontwenning vertoont, staat bekend als 'Data Mining'. Hier leest u hoe het de opbouw van een index beïnvloedt en waarom we voorzichtig moeten zijn. Dit is een gastpost van een expert op de financiële markten die om persoonlijke redenen anoniem wil blijven.
Veel van de lezers met een 'technische' achtergrond hebben altijd een positieve mening over datamining en terecht omdat data en datamining op verschillende gebieden wonderen hebben verricht - van dingen die zo simpel zijn als het begrijpen van klantgedrag om de verkoop te stimuleren tot het analyseren van weertrends om te voorspellen - data en datamining zijn zo nuttig geweest. In de context van Finance en Investment Management is 'Data Mining' echter een plaag.
Laat me in de context van Finance/Investment Management definiëren wat datamining is? Datamining is niets anders dan naar gegevens uit het verleden kijken zonder enige economische en intuïtieve grondgedachte, maar zoeken naar patronen in het bijzonder 'superieure' prestaties. Gezien de groei in rekenkracht en grootschalige beschikbaarheid van intraday-gegevens, is het niet erg moeilijk voor een half fatsoenlijke programmeur om eenvoudige scripts te schrijven om met duizenden, zo niet miljoenen backtests te komen om tot geweldige resultaten te komen. Zowel professionals als beleggers vergeten echter gemakshalve het meest centrale principe in investeringen:"Verleden is niet indicatief voor de toekomst", ondanks dat deze verklaring wordt weggegooid door iedereen die ooit een enkele voorraad of eenheid van een beleggingsfonds heeft gekocht.
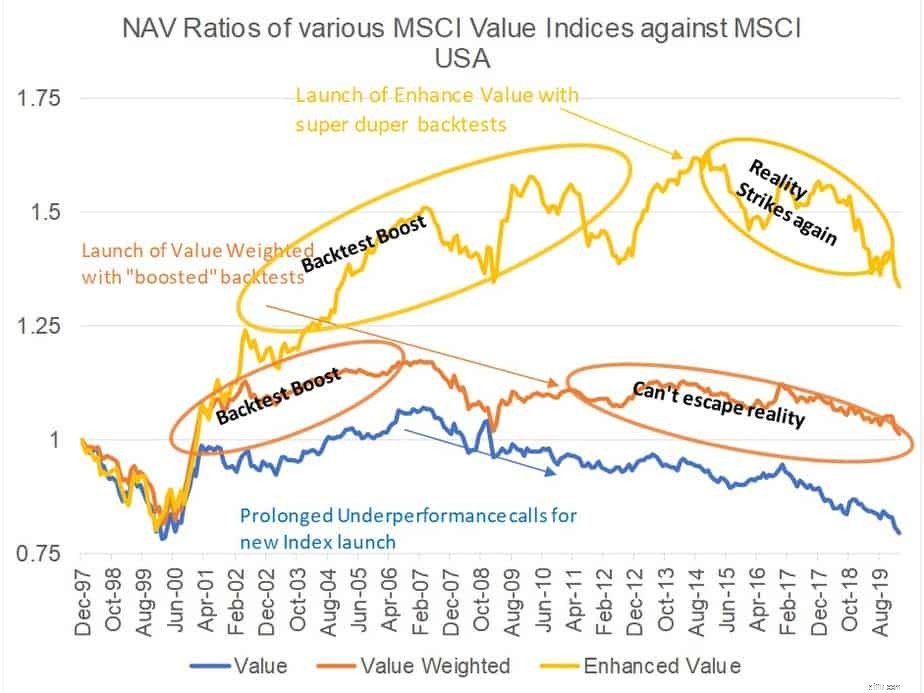
Hier is een illustratie van datamining in actie. MSCI, 's werelds grootste indexaanbieder - met biljoenen dollars die ofwel hun indices volgen of worden vergeleken met hun indices, heeft drie verschillende 'Value'-indices:MSCI Value-index, MSCI Value weighted index, MSCI 'Enhanced' Value-index. Elke logische persoon zou de volgende vragen stellen:Waarom zijn er drie verschillende waarde-indexen van dezelfde provider? In welke moet ik investeren? Wat zijn de verschillen tussen hen? Hoe is de een beter dan de ander? MSCI Value, het oudste lid van de familie, is live sinds 1997, de waardegewogen index werd gelanceerd in december 2010 en Enhanced Value in april 2015. Natuurlijk presteren de nieuw gelanceerde indices beter dan de oude indices in de backtests en dat zijn de "verbeteringen ”.
In de volgende afbeelding wordt de NAV-ratio van alle drie de waarde-indices uitgezet tegen de brede marktindex. De NIW-ratio, voor degenen die het niet weten, is slechts de verhouding van de ene index-NIW gedeeld door een andere index-NIW. De economische interpretatie van de ratio is de performance van een long-short portefeuille waarbij we ‘long’ gaan op de teller index/portefeuille en ‘short’ op de noemer index/portefeuille. Dus als de NAV-ratio stijgt, presteert de tellerindex beter dan de noemerindex (in dit geval de benchmark) en wanneer deze daalt, presteert de tellerindex slechter dan de noemer. Zoals u kunt zien, presteren de nieuwste indices aanzienlijk beter dan de oude, vooral in de backtests. Het is ook interessant om te zien dat nieuwe indices worden gelanceerd na een langdurige slechte prestatie van zijn voorgangers indices. Er is geen team van forensische analisten en onderzoeksjournalisten nodig om 2+3=5 samen te stellen. Als de indices eenmaal zijn gelanceerd en live gaan, wat is er dan met ze gebeurd? Dat is het resultaat van datamining. Niet-robuuste backtests die worden geplaagd door datamining zullen vroeg of laat hun ware kleur onthullen. Feit is dat de academische waardefactor al meer dan tien jaar ondermaats presteert. Geen enkele hoeveelheid datamining kan dat feit veranderen. Hoe we ook naar waarde kijken, er is geen ontkomen aan. Een fantastische prestatie uit het verleden is echter wat verkoopt. Een man moet eten, en om te eten moet hij verkopen, dus ..!
Je kunt je afvragen hoe we zo zeker zijn dat er datamining is? Waarom kunnen we ze niet het voordeel van de twijfel geven? Welnu, het is in de openbaarheid in hun methodologiedocumenten. Het volgende is een fragment over hoe MSCI verschillende variabelen kiest en hun gewicht bij het construeren van de factoren. Ze geven schaamteloos toe dat ze te zwaar wegen op variabelen die in de backtests een beter rendement/volatiliteit hebben laten zien. Dat is de tekstboekdefinitie van datamining en ze zeggen openlijk:ze doen aan datamining. Het kan maar één van twee dingen betekenen:1. Ze weten niet eens dat ze aan datamining doen. 2. Het kan ze gewoon niet schelen. Ik weet niet welke van de twee redenen gevaarlijker is dan de andere.
Dit is een screenshot van pagina 8 van het MSCI FaCS Methodology document

De tekst is hieronder weergegeven voor de duidelijkheid:
Lezers zullen vragen, dit zijn Amerikaanse gegevens, Amerikaanse indices, Amerikaanse provider - ik beleg gewoon in beleggingsfondsen in India, waarom zou het me iets kunnen schelen? Als het probleem zo overduidelijk voorkomt in indices, waarvan het trackrecord, de constructiemethode, de lanceringsdatum en het live trackrecord openbaar zijn, stel je dan de schaal en omvang voor van je favoriete actieve fondsen waarvoor je nergens toegang toe hebt. Er is nul transparantie. Indices zijn op regels gebaseerd en systematisch, terwijl actieve beleggingsfondsen volledig discretionair zijn. Ik kan onmogelijk de schaal doorgronden waarop datamining wijdverbreid zou zijn in de beleggingsfondsensector. Godzijdank heeft SEBI de regels bedacht om het aantal fondsen in elke categorie te beperken.
Dit wil niet zeggen dat we nooit iets terug moeten testen of nooit naar de prestaties van back-tests moeten kijken. Natuurlijk niet. Gegevens uit het verleden zijn de enige beschikbare informatie om beslissingen te nemen. We moeten het met een korreltje zout nemen. Zoals Pattu Sir zegt:"Het is verkeerd om de beste rendementen uit het verleden te plukken. Het ergste risico uit het verleden is voorzichtigheid. Dat is het eigenlijk wel. Een samenvatting van één regel van wat datamining wel en niet is. Dat is hoe wij als beleggers backtests of gegevens uit het verleden in het algemeen moeten behandelen - om risico's te begrijpen. Wat de industrie betreft:er is geen hoop.
Waarom adviseurs indexfondsen aanbevelen
Waarom je een Roth IRA nodig hebt
Wilt u een advocaat inhuren? Waarom lokaal het beste is.
Waarom u een huurdersverzekering nodig heeft
Waarom indexfondsen?
Waarom zijn we kwantitatieve investeerders?
Wat ik heb geleerd van mijn Facebook-gegevens - en waarom je die van jou moet zien